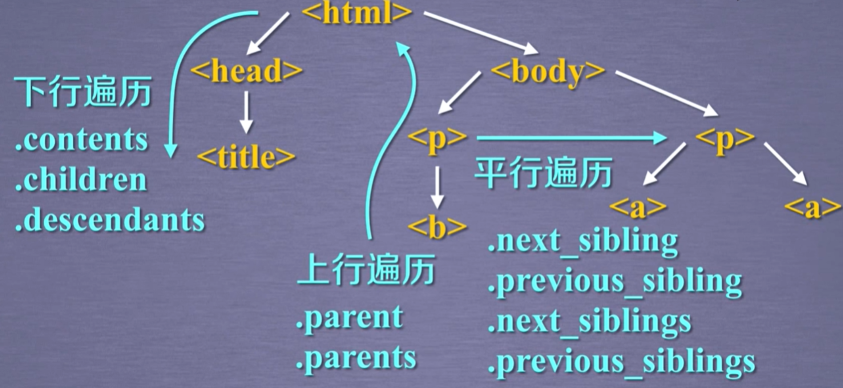
<head> <title>This is a python demo page</title> </head>
<body> <pclass="title"><b>The demo python introduces several python courses.</b></p> <pclass="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <ahref="http://www.icourse163.org/course/BIT-268001"class="py1"id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001"class="py2"id="link2">Advanced Python</a>.</p> </body>
import requests import re from bs4 import BeautifulSoup r = requests.get("https://python123.io/ws/demo.html") soup = BeautifulSoup(r.text,'html.parser') #查找HTML中的a标签 print(soup.findAll("a")) #查找HTML中的a与b标签 print(soup.findAll(['a','b'])) # #findAll参数为True时返回所有标签 for tag in soup.findAll(True): print(tag.name) # #利用正则表达式查找以b为开头的标签 for tag in soup.findAll(re.compile('b')): print(tag.name) #查找p中包含course属性的标签 for tag in soup.findAll('p',attrs='course'): print(tag) #查找属性域中包含link1的标签 for tag in soup.findAll(id='link1'): print(tag) #利用正则表达式查找属性域中所有包含link的标签 for tag in soup.findAll(id=re.compile('link')): print(tag) #在字符串区域中检索指定字符串 print(soup.findAll(string = 'Basic Python')) print(soup.findAll(text="Basic Python")) print(soup.findAll(text=re.compile('python')))